|
Safal Shrestha
Efficient reasoning systems for LLMs and agents
I am a research assistant at New York
University Abu Dhabi, working on efficient reasoning systems: how LLMs
and agents can reason, adapt, and generalize under realistic data, compute, and
cost constraints.
Through July 2026, I am in the Deep Learning Lab with Prof. Keith
Ross. After that, I will join the CIDSAI lab at NYUAD in a similar research
role with Prof. Pierre Youssef.
Email /
CV /
Scholar /
Github
LLM reasoningAI efficiencytest-time scalinginterpretability
|

|
News
| Feb 2026 |
Started a project on cost-aware orchestration
of heterogeneous LLM agents for long-horizon deep-search tasks. |
| Feb 2026 |
Two new papers on Layer Pruning and Failure-Prefix Conditioning are out on arXiv!
|
| Nov 2025 |
Attended EMNLP 2025 to present our paper "Warm Up
Before You Train". |
|
Research
My research studies efficient reasoning systems: models and agents that
reason reliably while using limited data, compute, and cost budgets. I approach this through
three connected directions:
- Diagnosing reasoning failures: when and why LLMs fail to generalize
on mathematical, logical, and code-like tasks.
- Improving reasoning efficiently: sample-efficient post-training,
distillation, failure-driven learning, and model-internal analysis.
- Scaling agents cost-effectively: routing work across heterogeneous
models, plans, and verifiers so test-time compute is spent where it matters.
|
Current Direction
I am especially interested in AI efficiency and cost savings for reasoning systems. My
current project asks whether a system can learn to orchestrate a pool of large and small
browsing agents, choosing when to spend extra test-time compute and when cheaper,
redundant runs are enough.
This line of work connects my prior projects on reasoning failures, RL/distillation,
critical layers, and layer pruning with a new question: when is more computation
actually worth it?
|
|
|
On the Limits of Layer Pruning for Generative Reasoning in
LLMs
Safal
Shrestha,
Anubhav Shrestha,
Aadim Nepal,
Minwu Kim,
Keith Ross
arXiv, 2026
arXiv
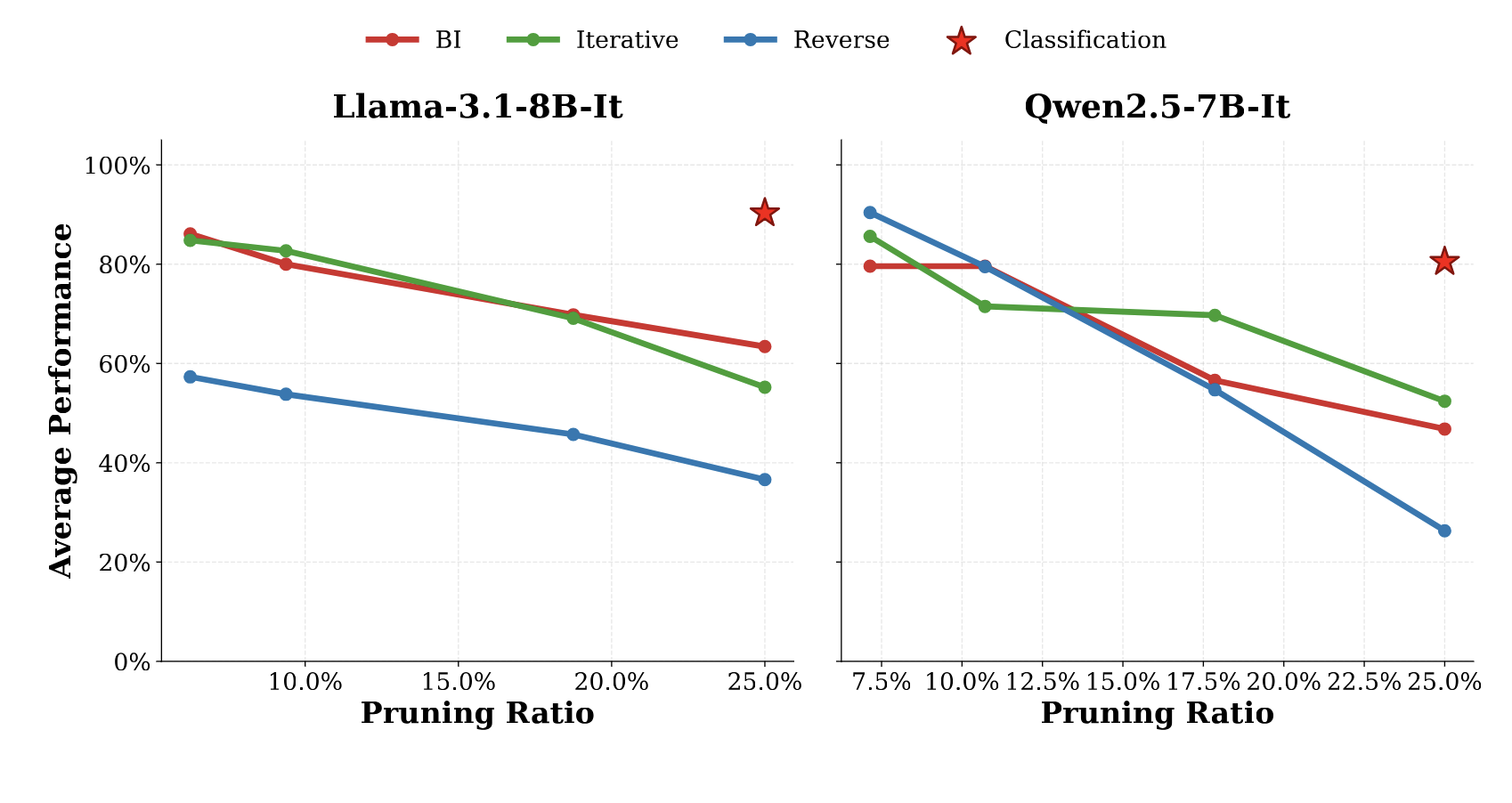
Existing layer pruning techniques often suffer severe degradation on generative reasoning
tasks. Through a systematic study, we find that tasks requiring multi-step reasoning are
particularly sensitive to depth reduction, exhibiting degradation in critical algorithmic
capabilities like arithmetic and code synthesis.
|
|
|
Training Reasoning Models on Saturated Problems via Failure-Prefix
Conditioning
Minwu Kim,
Safal
Shrestha,
Keith Ross
arXiv, 2026
arXiv
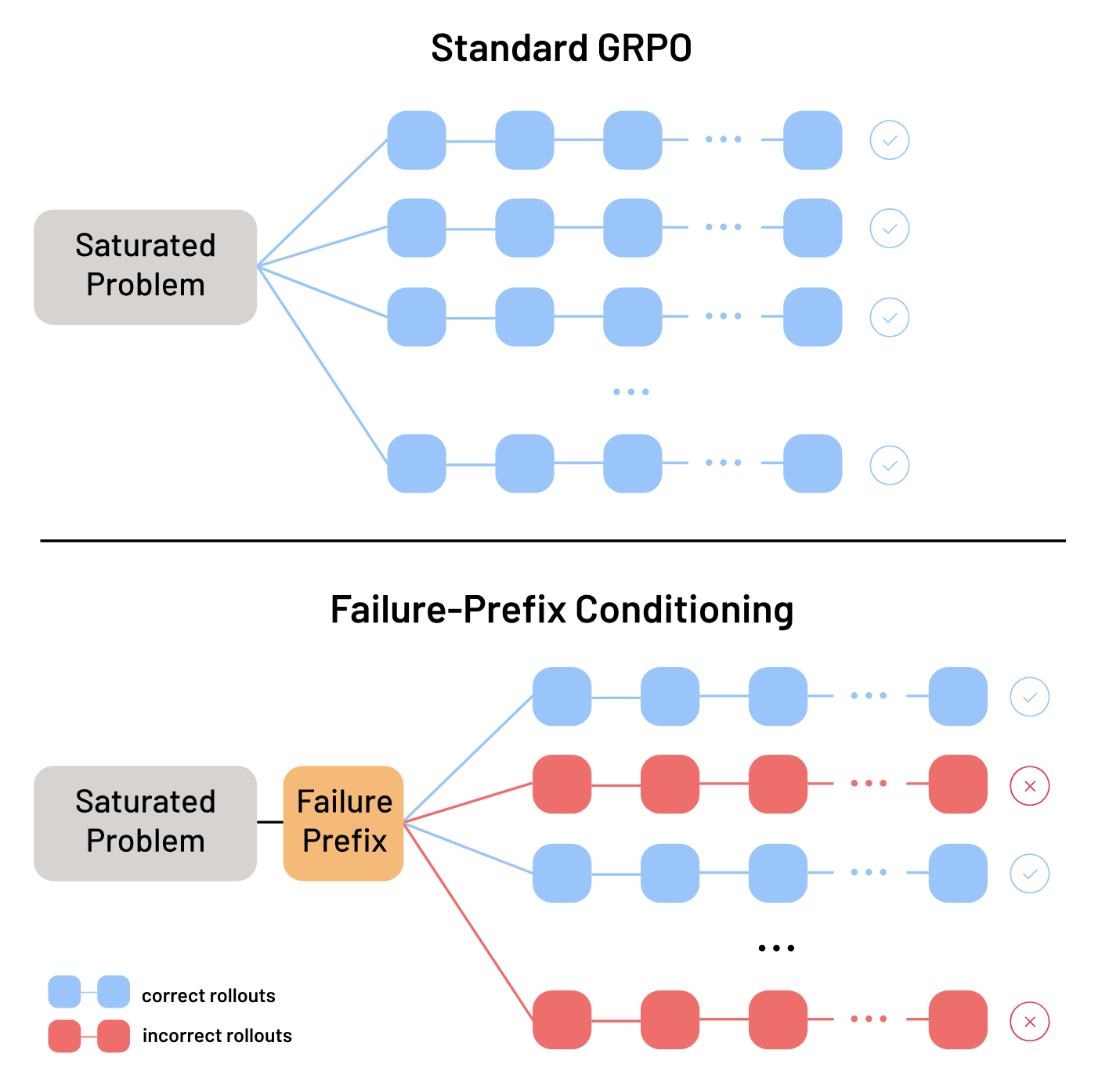
We identify that training reasoning models stalls on saturated problems because informative
failures are rarely encountered. We propose failure-prefix conditioning, which reallocates
exploration by conditioning training on prefixes from rare incorrect reasoning trajectories,
matching performance gains of medium-difficulty problems.
|
|
|
Warm Up Before You Train: Unlocking General Reasoning in
Resource-Constrained Settings
Safal
Shrestha,
Minwu Kim,
Aadim Nepal,
Anubhav Shrestha,
Keith Ross
EMNLP, 2025
arXiv
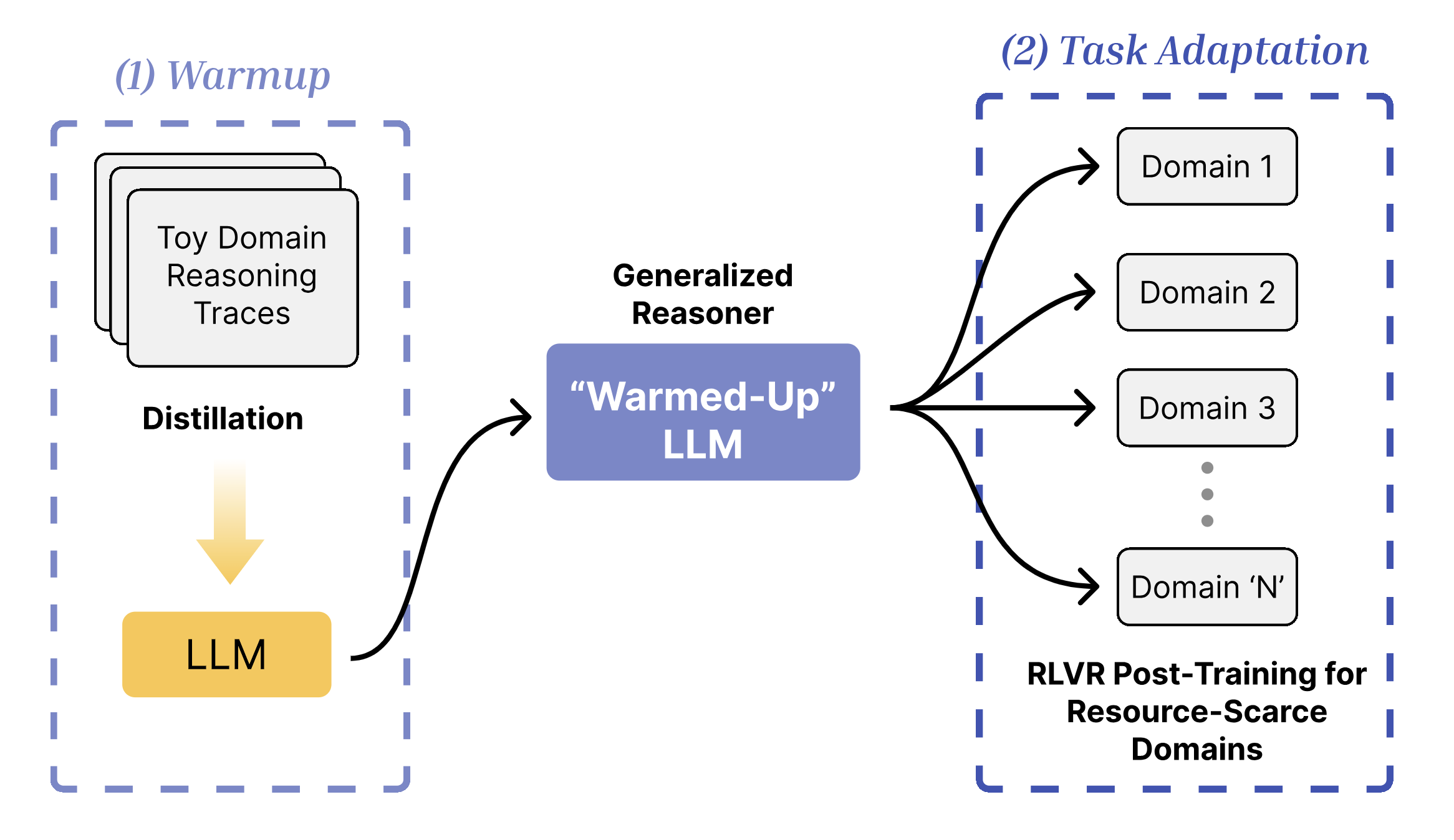
We find that distilling (warming up) a LLM with non-domain-specific reasoning traces (like a
logic game) can bring general improvements across multiple reasoning-intensive tasks like
math and coding. Reinforcement Learning on top of it leads to better sample efficiency,
generalizability, and final performance.
|
|
|
Layer Importance for Mathematical Reasoning is Forged in
Pre-Training and Invariant after Post-Training
Aadim Nepal,
Safal
Shrestha,
Anubhav Shrestha,
Minwu Kim,
Keith Ross
BlackboxNLP Workshop, EMNLP, 2025
MATH-AI Workshop, NeurIPS, 2025
arXiv
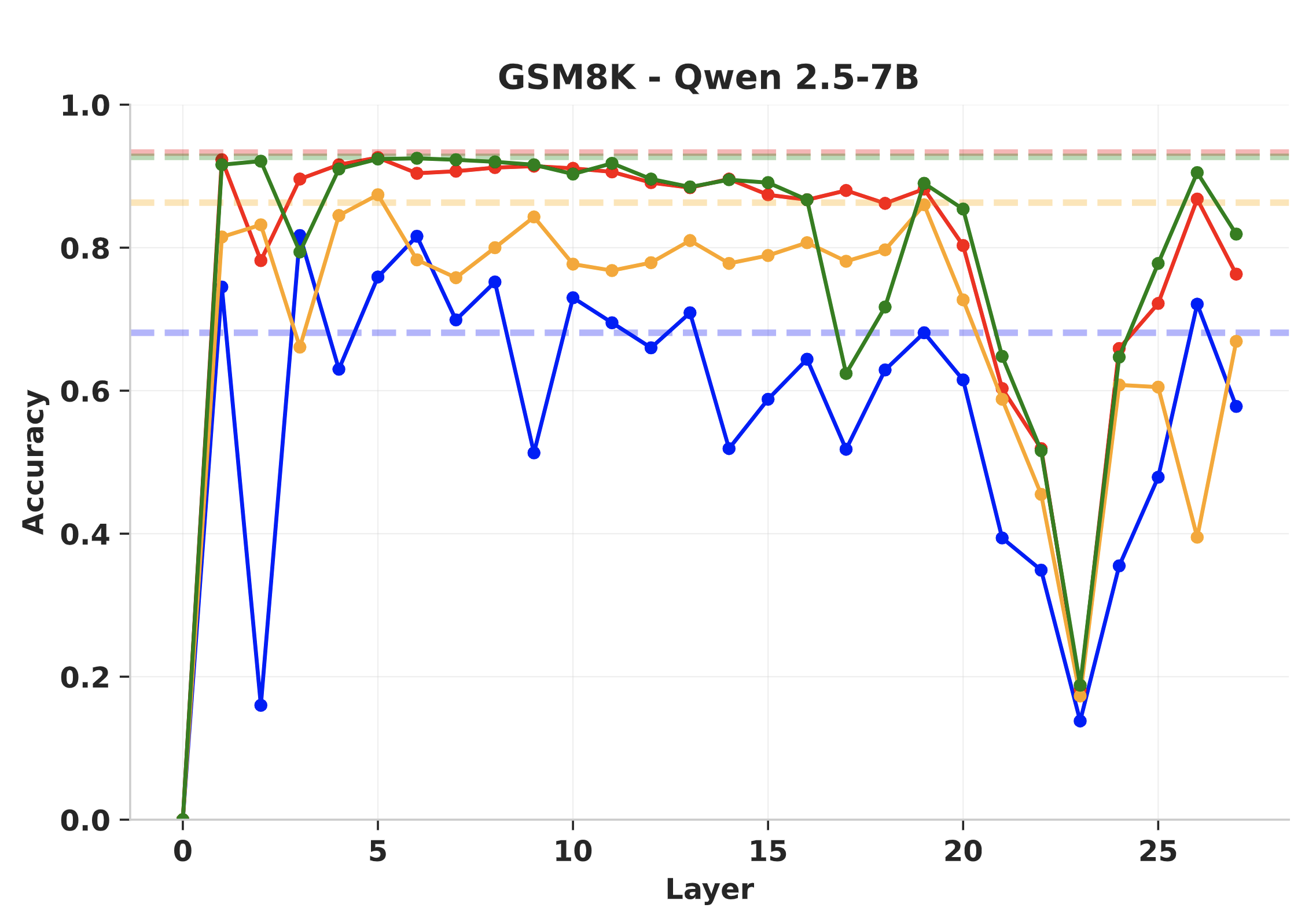
We find that LLMs form critical layers during pretraining whose removal completely destroys
performance. Furthermore, the importance of such layers remain unchanged after post-training
regimes like Reinforcement Learning, Distillation, and Instruction Tuning.
|
|
|
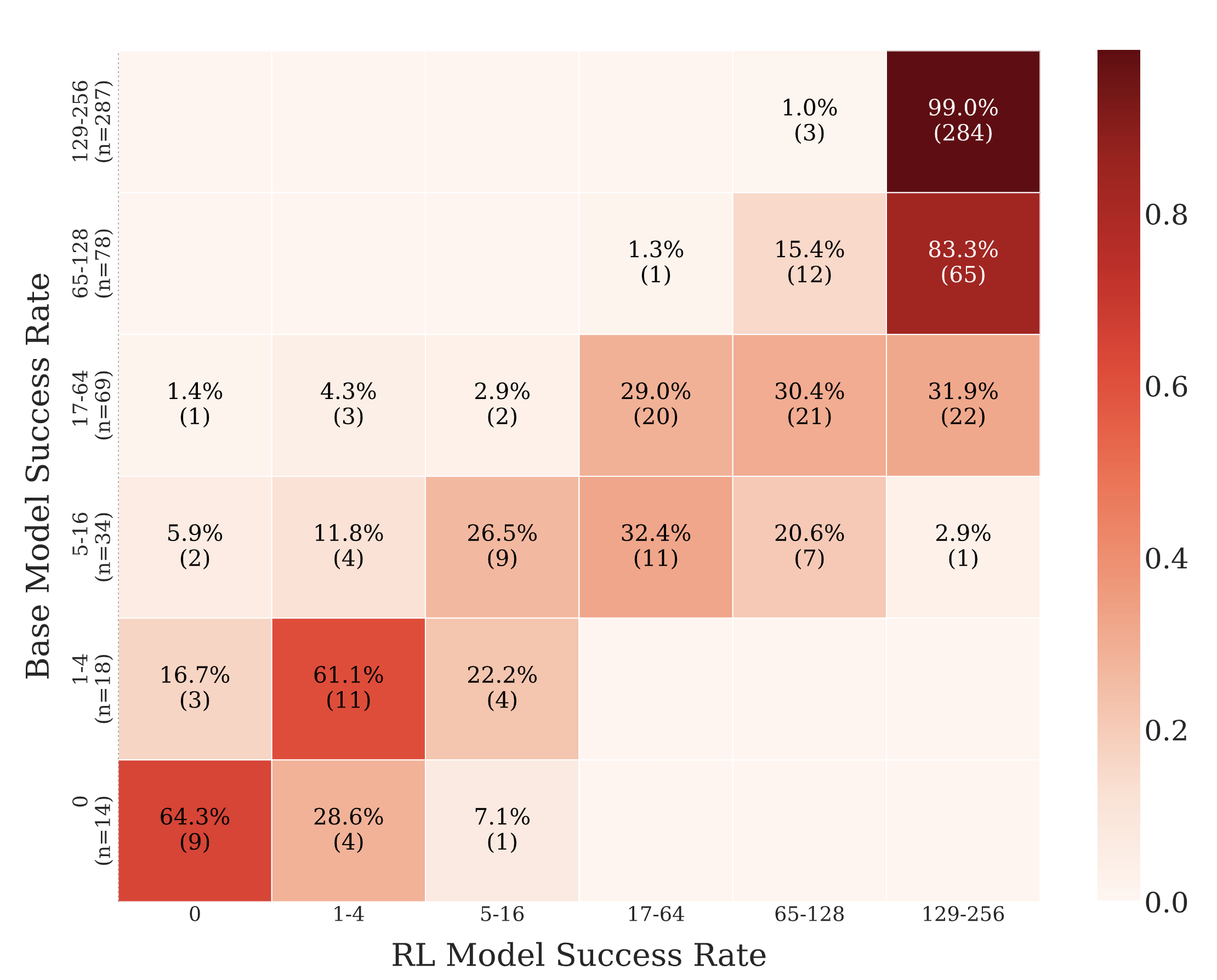
Reinforcement Learning vs. Distillation: Understanding Accuracy and
Capability in LLM Reasoning
Minwu
Kim*,
Anubhav
Shrestha*,
Safal
Shrestha,
Aadim Nepal,
Keith Ross
MATH-AI Workshop, NeurIPS, 2025
arXiv
We investigate why RL with verifiable rewards boosts accuracy but not capability, revealing
it improves easy questions at the cost of hard ones—while distillation improves both only
when new knowledge is introduced.
|
|
|
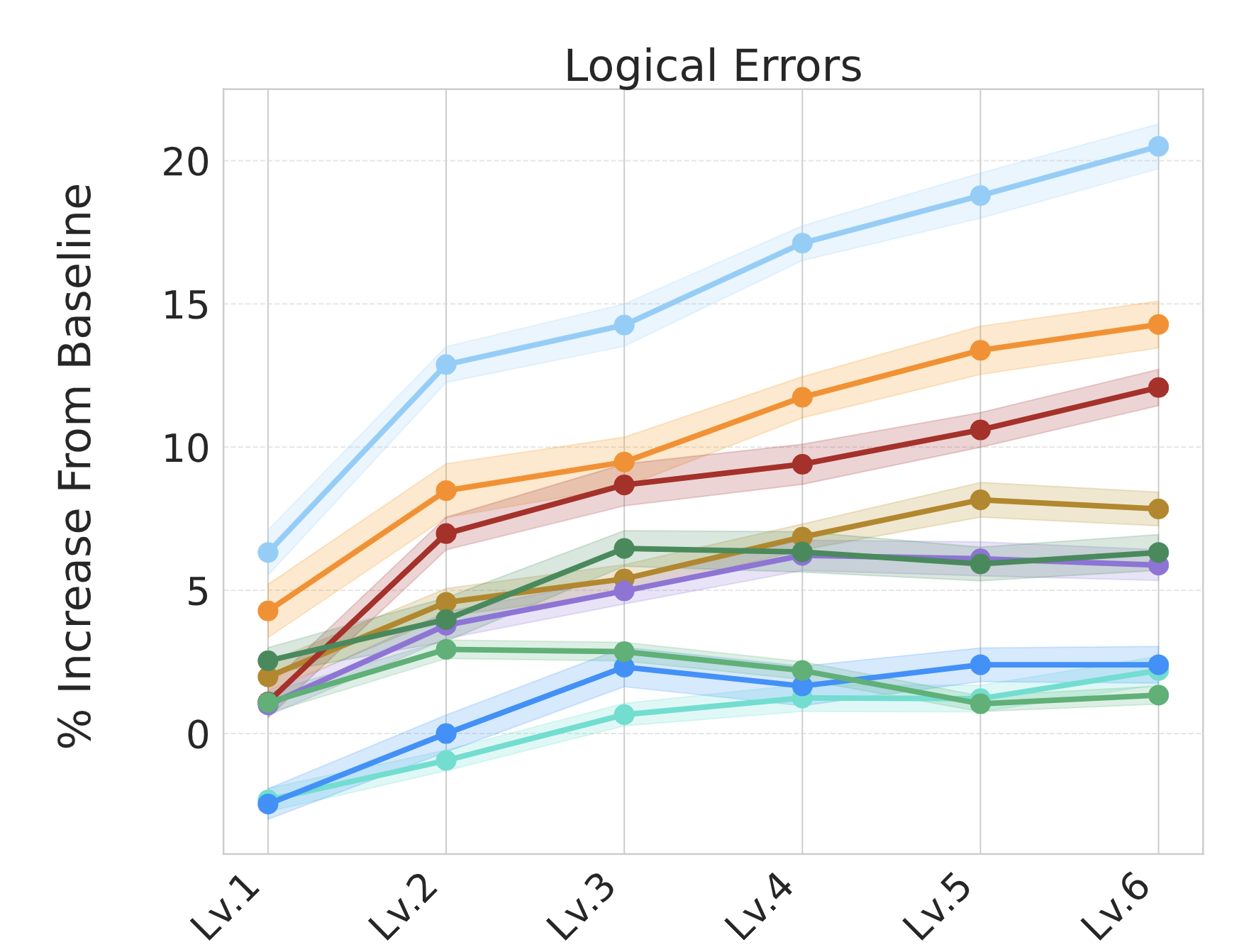
Mathematical reasoning in large language models: Assessing logical
and arithmetic errors across wide numerical ranges
Safal
Shrestha*,
Minwu
Kim*,
Keith Ross
arXiv, 2025
arXiv
We find that as you increase the magnitude of numbers in simple math problems, LLMs get more
confused and commit logical errors (along with the expected arithmetic errors).
|
|
|